Our Platform Updates
February 2023
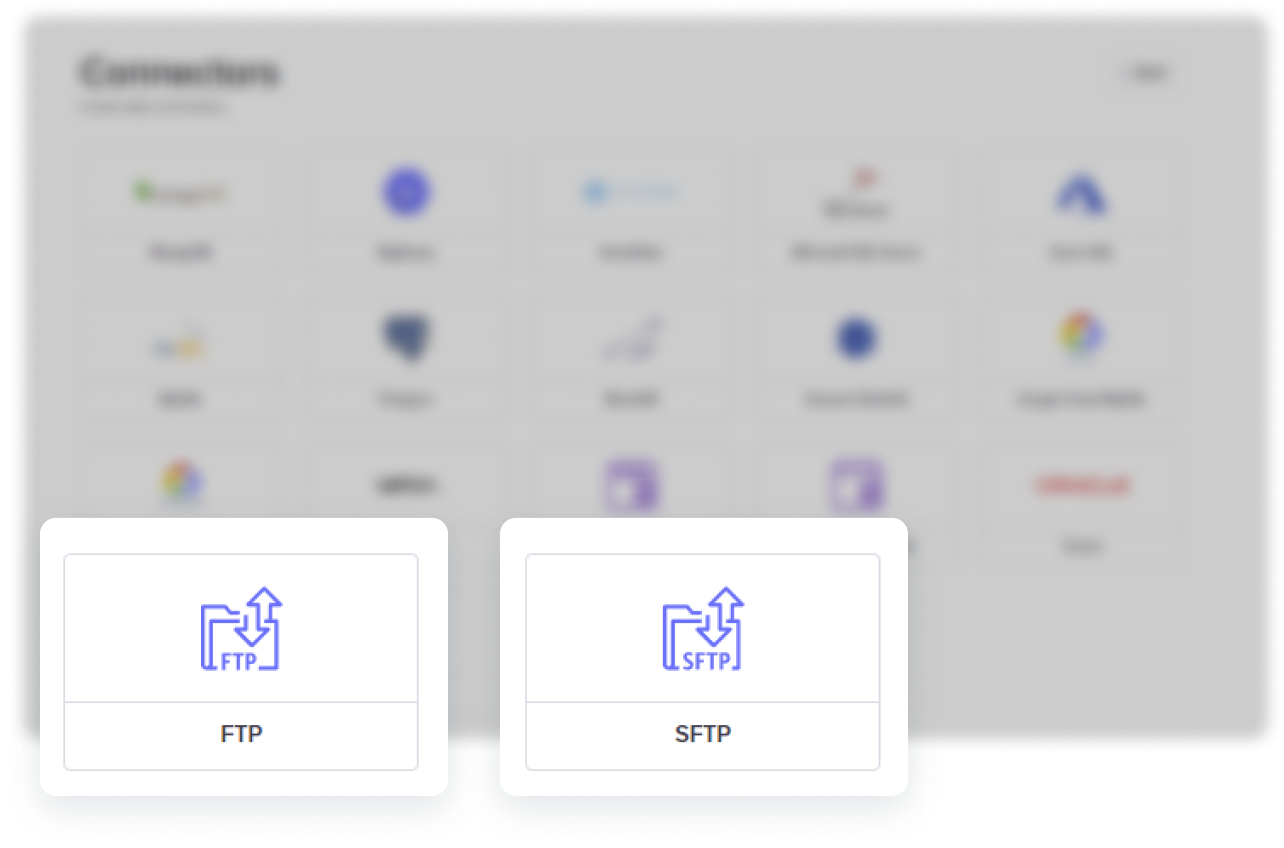
Connectors
Functionalities
- FTP
- SFTP
These are data integration functionalities that enables the end-user to connect and ingest data from SFTP servers as well as provides the platform with access to the desired destinations where data can be written into when transformed or cleaned on the platform.
January 2023
Connectors
Functionalities
- Oracle
- Amazon S3 Buckets
These are data integration functionalities that enables the end-user to connect and ingest data from Amazon S3 as well as provides the platform with access to the desired destinations where data can be written into when transformed or cleaned on the platform.

October 2022
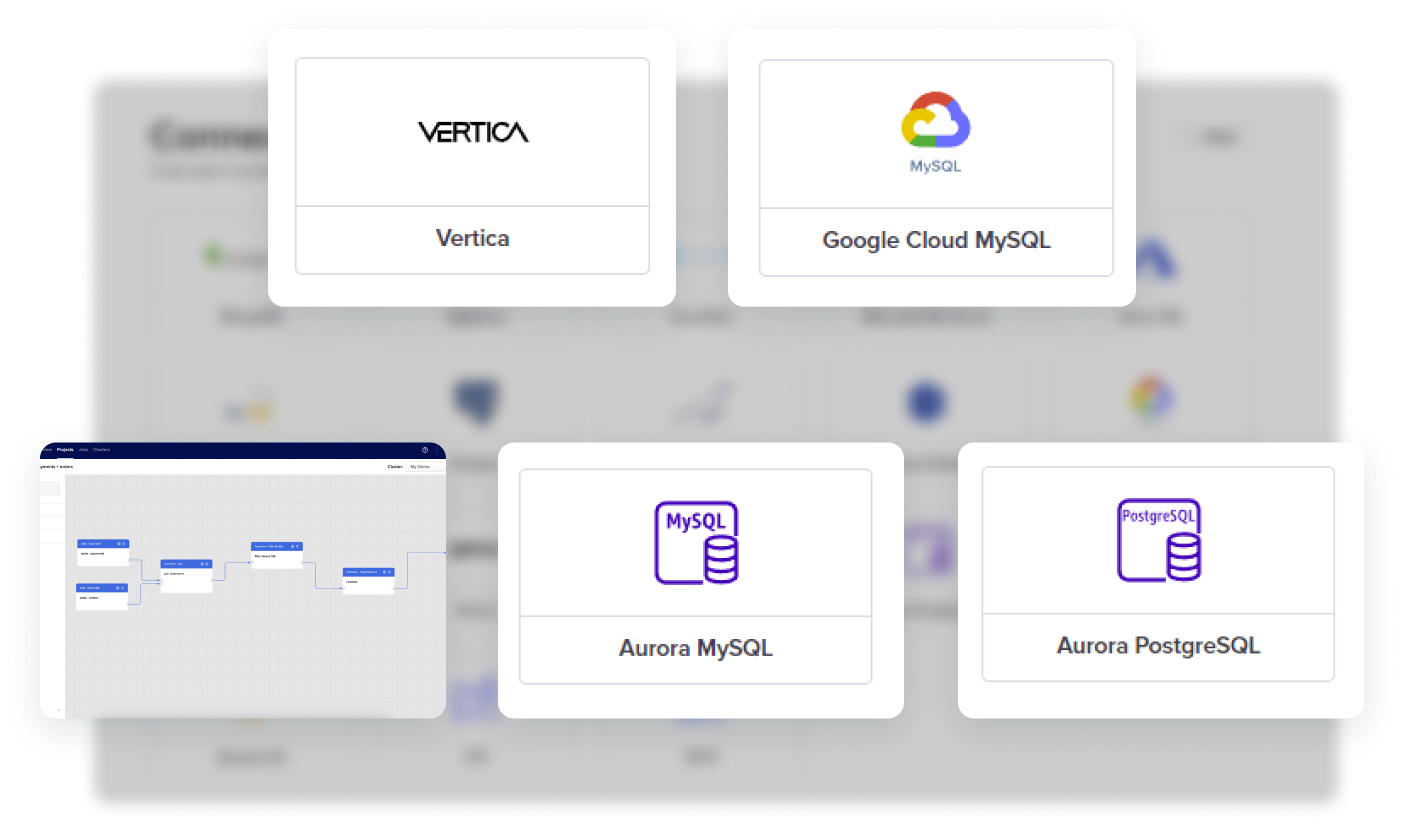
Connectors
Functionalities
- Vertica
- Google Cloud MySQL
- Google Cloud PostgreSQL
- Aurora MySQL
- Aurora PostgreSQL
These are data integration functionalities that enables the end-user to connect and ingest data from Amazon S3 as well as provides the platform with access to the desired destinations where data can be written into when transformed or cleaned on the platform.
August 2022
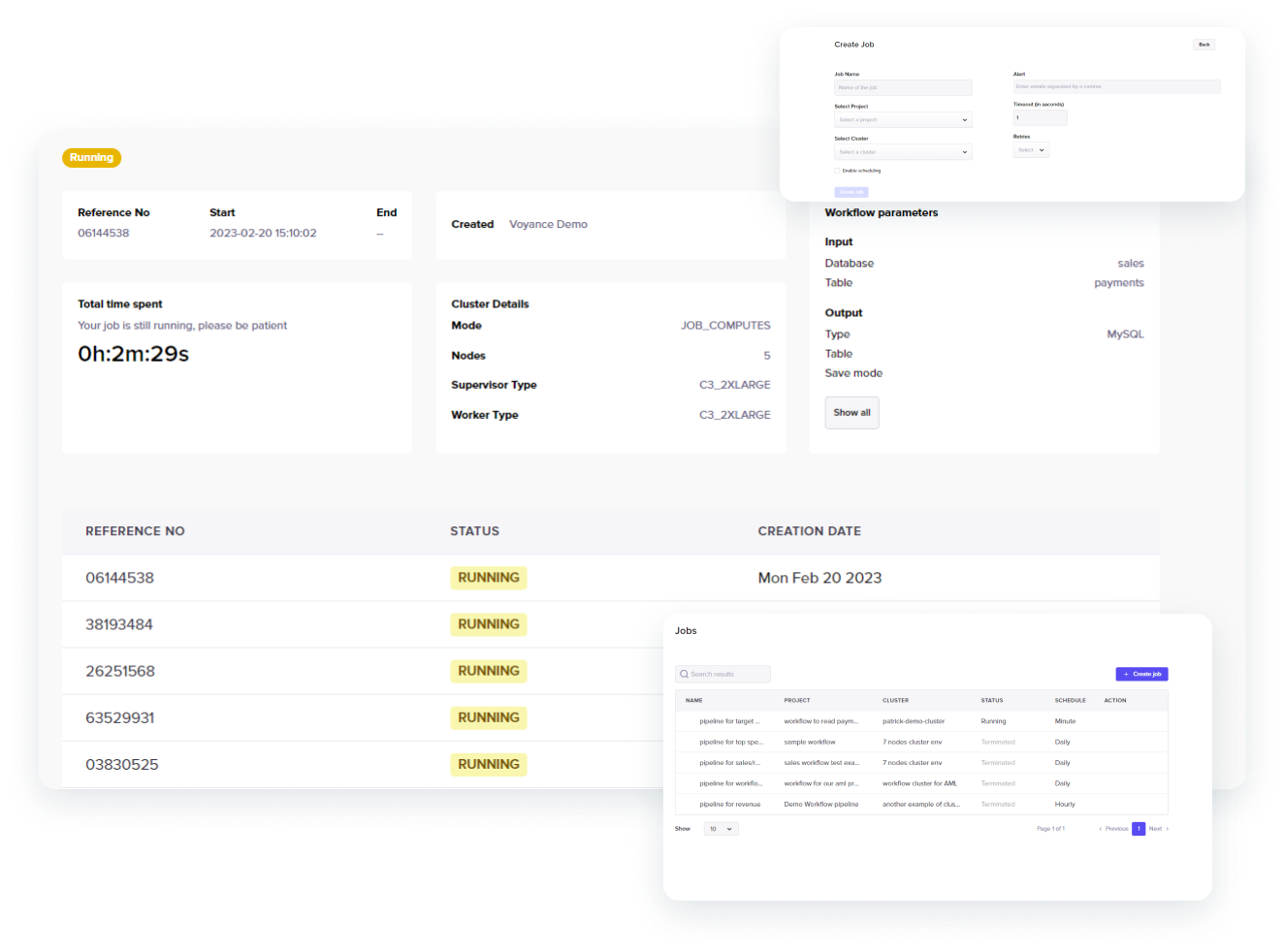
Jobs
Functionalities
Jobs is a distributed orchestration workflow engine that takes the designed transformation and orchestrate it on a provisioned cluster of machines enables to end-user to automate the processing of the data pipelines without of manual execution.
June 2022
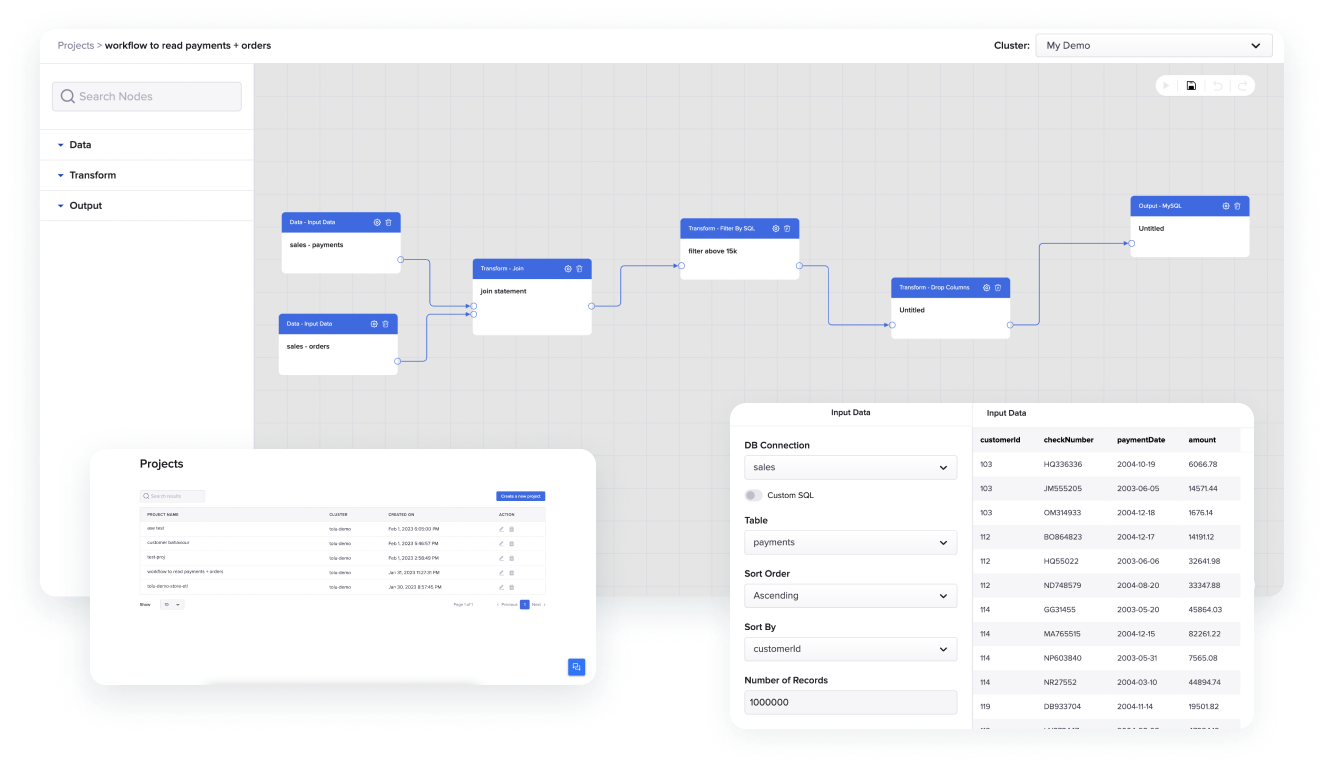
Workflow manager
Functionalities
This feature allows end-users to design, test and execute data integration, wrangling, transformation, clean and sinking data into different destinations of their choice from an interactive user interface without the need of extensive code implementation from a canvas.
March 2022
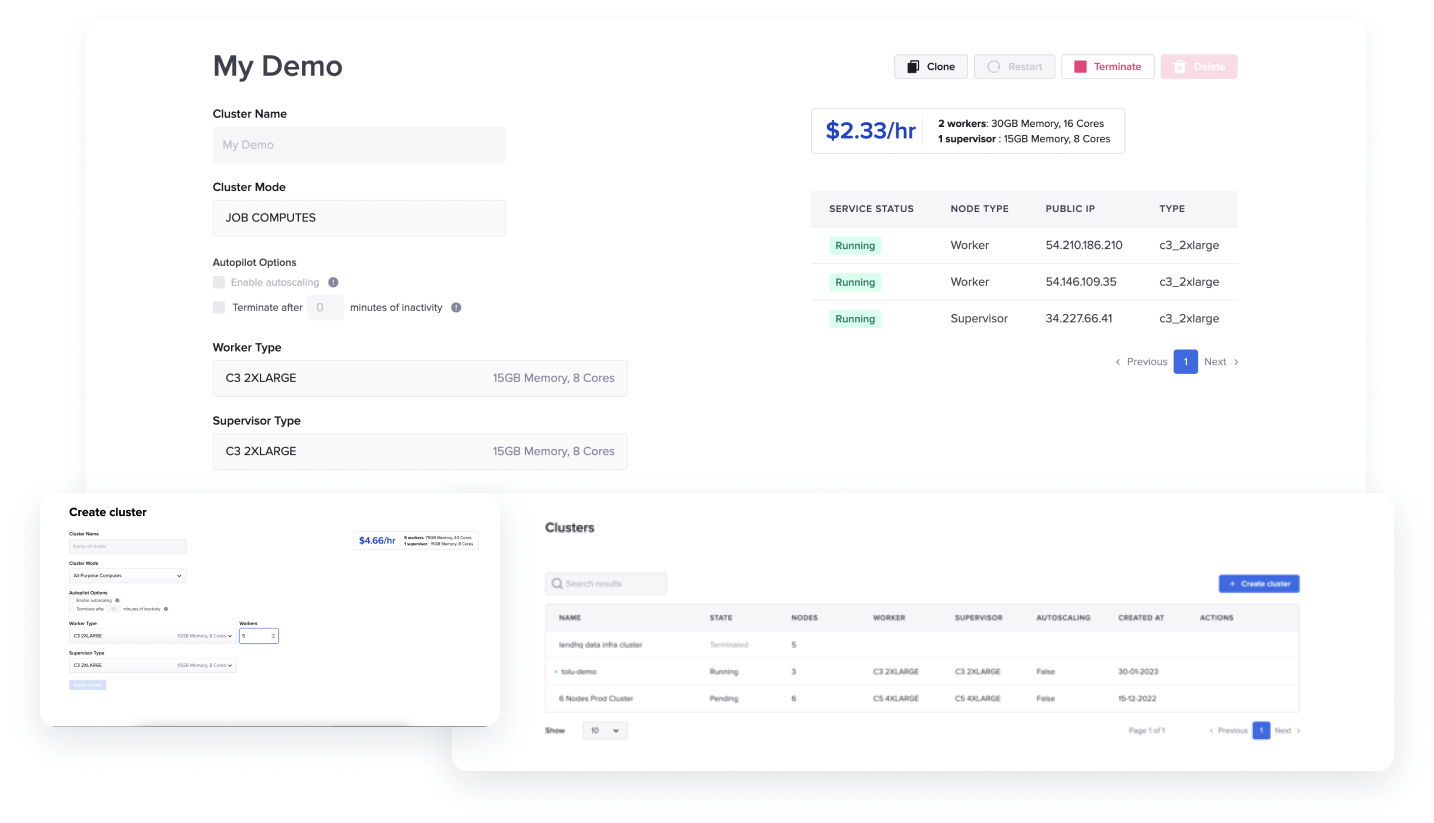
Cluster Provisioner
Functionalities
Cluster provisioner: This feature allows end-users to provider compute machines that enables to deployment data engineering workloads to specific cluster of machines of their choice.
July 2021
Platform Core
Functionalities
- SSO modules
- Auth
- Platform orchestrator
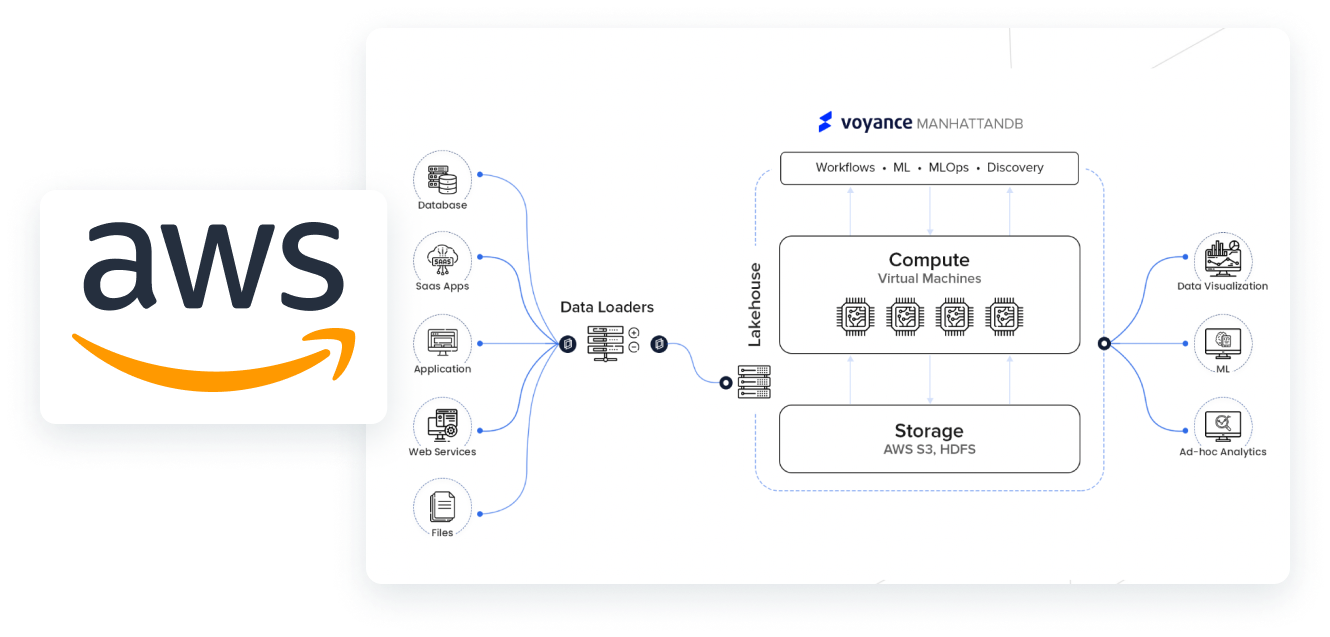
- Support for AWS
Platform Core
- SSO modules: This feature allows end-users to access the platform using their existing credentials from other systems, such as Google, Facebook, or LinkedIn, rather than having to create a separate account for the platform. This helps to simplify the login process and reduce the number of passwords users need to manage.
- Auth: Auth: This feature provides a robust authentication and authorization framework, enabling end-users to manage and control access to the platform's resources. It includes support for various authentication methods, such as username and password, OAuth, and SAML, as well as role-based access control, allowing administrators to grant permissions and restrict access to specific resources based on users' roles and responsibilities.
- Platform orchestrator: This feature provides a centralized management console for end-users to deploy and manage data processing workflows across different environments, including on-premises and cloud-based infrastructures. The platform orchestrator provides a range of features, including workload scheduling, resource management, and job monitoring, enabling users to manage their data pipelines more efficiently and effectively.
- Support for AWS: This feature enables end-users to deploy and run the platform on Amazon Web Services (AWS), providing access to a wide range of AWS services and resources. The platform is designed to take full advantage of AWS's scalability, reliability, and security features, enabling users to process large volumes of data and deliver high-performance data processing workflows with ease.